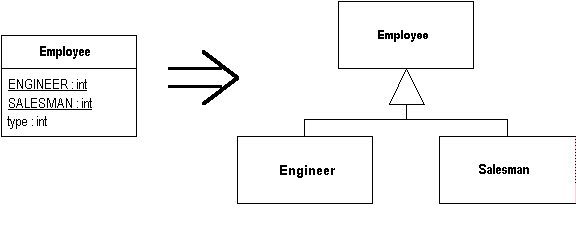
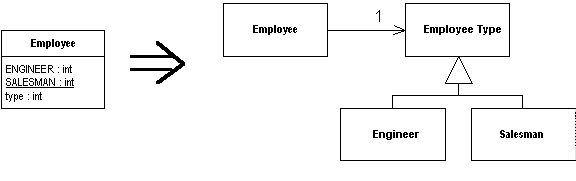
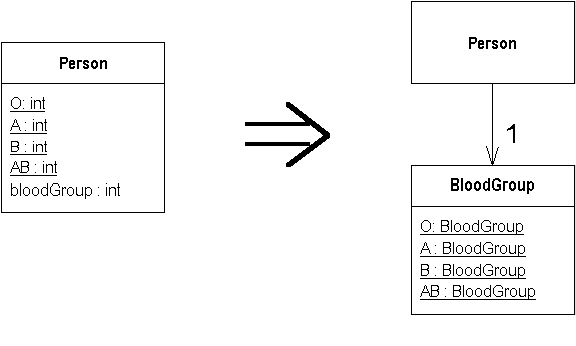
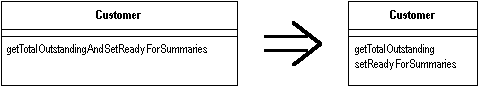1. What is a DOI?
A Digital Object Identifier -- a
digital identifier for any
object of intellectual property. A DOI provides a means of persistently identifying a piece of intellectual property on a digital network and associating it with related current data in a structured extensible way.
A DOI can apply to any form of intellectual property expressed in any digital environment. DOIs have been called "the bar code for intellectual property": like the physical bar code, they are enabling tools for use all through the supply chain to add value and save cost.
A DOI differs from commonly used internet pointers to material such as the URL because it identifies an object as a first-class entity, not simply the place where the object is located. The DOI identifies an entity directly, not some attribute of an object (an address is an attribute of a thing, whereas the thing itself is a first class object).
A DOI also differs from commonly used identifiers of intellectual property such as standard bibliographic and related identifiers (ISBN, ISRC, etc) because it can be associated with defined services and is immediately actionable on a network.
A DOI is an implementation of the Internet concepts of Uniform Resource Name and Universal Resource Identifier. A DOI differs from abstract naming specifications such as URI in that it is a defined implementation complete with social and technical infrastructure, ready to use.
For more on this topic, see the
DOI Handbook chapters
Introduction and
Numbering.
2.What can be identified by a DOI?
A DOI can be used to identify any resource involved in an intellectual property transaction. Intellectual property includes both physical and digital manifestations, performances and abstract works. An entity can be identified at any arbitrary level of granularity. DOIs can be used to identify, for example, text, audio, images, software, etc; and in future could be used to identify the agreements and parties involved. While the scope of intellectual property transactions is quite broad, it is unlikely that DOIs would be appropriate for identifying entities such as people or natural objects or trucks
unless they are involved in such a transaction. Intellectual property transactions don't necessarily involve money: DOIs can be used to identify free materials and transactions as well as entities of commercial value.
A DOI is an implementation of URI (Uniform Resource Identifier, sometimes called Universal Resource Identifier, IETF RFC 2396). It uses the Handle system for resolution of the identifier, and the indecs framework for metadata description. The syntax of the DOI is specified by a NISO standard, (ANSI/NISO Z39.84).
While a DOI can therefore be used like any other URI to identify "anything that has identity", the DOI system is a combination of components (identification, resolution, metadata and policies) devised with the specific primary aim of identifying any "
intellectual property entity". The initial focus of DOI applications was "Creations" -- that is, resources made by human beings, rather than other types of resource (natural objects, people, places, events, etc). However these other types of resource are also necessarily involved in intellectual property transactions, and so may be identified by DOIs where appropriate. As an example, the initial aim of DOI was not to be used to identify natural objects (e.g. specimens in a natural history museum, or natural substances used in pharmaceutical research): but if these were involved in intellectual property interactions there may be an application of DOI to museum artefacts or pharmaceutical components which would be appropriate. Similarly, DOI was not initially an identifier for agreements or licences, but implementers may find it useful to identify these with DOIs alongside the intellectual property that they govern.
Formally, DOI scope is defined in terms of a data model underlying the indecs analysis: a DOI can be assigned to any entity which is a Resource within the indecs model of e-commerce. This means the type of entity must be described in terms of attributes in the dictionary (e.g., media, mode, content, subject), and become an entry in the indecs Data Dictionary used by the DOI system. The practical outcome of this is important and provides a pragmatic
functional specification: a DOI can identify any Resource, but the DOI system requires that the Resource is defined (technically and hence precisely) in terms of agreed public (iDD) attributes. This is one role of the DOI metadata.
Within the world of intellectual property entities as resources, the primary focus of DOI has been on the identification of a Creation. The metadata component of the DOI uses the concept of a Kernel set of metadata. The kernel metadata as currently defined relates only to Creations, and a different kernel will need to be defined for fundamentally different Resources or entities such as parties, places or agreements. There is no problem in principle in doing this as the concepts are analogous; it may be a logical and necessary step (e.g. if a DOI Registration Agency wishes to use DOIs to identify individual licence agreements, authors, consumers, etc).
For more on this topic, see the
DOI Handbook chapter
Introduction.
3. How do I assign a DOI?
A DOI prefix (for example, 10.1000/) enables a registrant to assign many DOIs, by building on the prefix to construct a range of unique identifiers (10.1000/abc, etc). To obtain a DOI Prefix, you need to work either with a DOI Registration Agency or, for experimental or prototype purposes, with the International DOI Foundation.
Working with a Registration Agency brings with it the advantages of participation in a defined DOI application with others. Several DOI Registration Agencies have been appointed, and additional DOI Registration Agencies will be appointed.
DOIs allocated using prefixes purchased directly from IDF are registered without structured metadata: there is no metadata support and no social infrastructure support of the type which can be given by a Registration Agency. DOI prefixes obtained directly from IDF may however be useful if you wish to experiment in developing your own applications. Prefixes will only be issued using the direct route at the discretion of the IDF.
For more on this topic, see the
DOI Handbook chapters
Registration Agencies and
Operating Procedures.
4. How much does it cost to assign a DOI?
Registration Agencies (RAs) are free to set fees independently of the IDF. This allows a range of pricing and business models using third part registration agencies, in recognition of the fact that a simple model is not a "one size fits all" solution. Many RAs will be assigning DOIs as part of a wider service offering to customers in which DOI registration may not be a separately specified item. Registration Agencies participate in the DOI System by paying fees (of the order of a few cents per DOI) to support central activities of the IDF.
There is no limitation placed on the number of DOI prefixes that any organization may choose to apply for. DOI Prefixes will only be issued using the direct route at the discretion of the IDF.
For more on this topic, see the
DOI Handbook chapters
IDF,
Registration Agencies, and
Operating Procedures.
5. Why do I need a Registration Agency to assign DOIs?
Registration Agencies (RAs) are established to provide services on behalf of specific user communities. CrossRef, for example, is providing citation-linking services for the scientific publishing sector, so publishers will choose CrossRef as their Registration Agency if they wish to use the specific service or services offered by CrossRef. Choosing an appropriate RA will give you access to DOI services and implementations offered by the RA for that community.
RAs may offer sectoral specialisms of this kind, which may have global application; or may offer regionally based services such as local language support. The smooth running of the DOI System requires close collaboration between different RAs so that registrants can avail themselves of the full range of services that are offered.
If you cannot identify an appropriate Registration Agency able to meet your specific needs please contact us. The IDF will act as a "default" Registration Agency for the foreseeable future, to host registration of such DOIs until an appropriate Registration Agency can take over. IDF can also form working groups of like-minded organisations who may wish to establish a collaborative activity to form an RA, and stimulate the development of business opportunities. It will not compete with RAs that have an established market position.
For more on this topic, see the DOI Handbook chapter Registration Agencies.
For more on this topic, see the
DOI Handbook chapter
Registration Agencies.
6. How do I become a member of the International DOI Foundation?
Members of the DOI Foundation are organizations (not usually individuals). Membership requires payment of an annual subscription, which varies by category of membership. The International DOI Foundation is similar in some ways to other development organisations such as the World Wide Web consortium.
For more on this topic, see the
DOI Handbook chapter
Introduction.
7. What is resolution and why is it important?
The process in which an identifier is the input (a request) to a network service to receive in return a specific output of one or more pieces of current information (state data) related to the identified entity: e.g. a location (such as URL) where the object can be found. A name (or unique identifier) for a digital object enables that name to be resolved to one (or many) of several different pieces of data which may be associated with the digital object. Such pieces of data can be locations of the object, or services about the object, or any other defined piece of data. Resolution enables a single name (the identifier, DOI) to be used persistently to manage the object, even if any of those pieces of data (like location) change. Resolution therefore (a) enables persistence and (b) enables multiple services to be directly associated with the DOI.
For more on this topic, see the
DOI Handbook chapter
Resolution.
8. What is metadata and why is it important?
Metadata is related data about the object. Identifiers are simply names -- names that follow a strict convention and are unique if properly applied, but names just the same. Unique identifiers are particularly valuable in machine-mediated commercial environments, where unambiguous identification is crucial.
Some identifiers tell you something about the thing that they identify -- for example, since "ISBN" is the acronym of "International Standard Book Number", the identifier "ISBN 1-900512-44-0" can reasonably safely be assumed to identify a book (always assuming that ISBN rules have been correctly followed, which is not universally the case). However, to find out
which book it identifies, it is necessary to consult metadata -- the identifier links the metadata with the entity it identifies and with other metadata about the same entity. Metadata is an integral part of making the identifier useful.
For more on this topic, see the
DOI Handbook chapter
Metadata.
9. Who is using the DOI system today?
Several hundred different registrant organizations have so far allocated several million DOIs. Because the origins of the DOI were in the text sector, an initial large implementation covering half of these registrants was from traditional print-publishing companies that have already established major online publishing programs.
However the fundamental design of the system is applicable to any media or content. The IDF is working closely with many businesses in other sectors of the "content industries" to extend the application of the DOI to many other types of intellectual property.
For more on this topic, see the
DOI Handbook chapter
Registration Agencies.
10. What is the role of the International DOI Foundation?
The IDF governs the DOI System, to ensure that all applications follow common rules. The system itself has several components: the technology is based on open agreed standards, while the infrastructure is defined by agreements between the various organisations which run the system, such as the Registration Agencies and the technology providers. Each Registration Agency is autonomous and the IDF has no role in determining an RAs business model or governance.
The Foundation was created in 1998 and supports the development and promotion of the Digital Object Identifier system as a common infrastructure for content management. The Foundation is controlled by a Board elected by the members of the Foundation, with an appointed full-time Director who is responsible for co-ordinating and planning its activities. Through the elected Board, the activities of the Foundation are ultimately controlled by its members. Membership is open to all organizations with an interest in electronic publishing and related enabling technologies.
For more on this topic, see the
DOI Handbook chapter
The International DOI Foundation.
11. Are there any guidelines on how to make up the identifier?
The DOI syntax is a NISO standard, but allows the incorporation of any form of existing identifier. The DOI suffix can be any alphanumeric string that the Registrant chooses. This can simply be a sequential number, or it can make use of an existing (legacy) identifier. The latter may often be administratively convenient for the Registrant.
For more on this topic, see the
DOI Handbook chapter
Numbering.
12. Does a DOI include a check digit?
A check digit is not compulsory or necessary, but if you wish to include one you may. Identifiers such as URL and URI specifications, deriving from an Internet environment, do not have check digits: the underlying TCP/IP protocol they use has an error-correction component. Identifiers such as ISBN and similar bibliographic or documentation identifiers do have check digits: these act as aids to readability or keyboard data entry in the absence of any automated protocol correction.
DOI is deliberately designed as an opaque string, so that it is suitable for any use. The DOI system does not itself make use of check digits. However, other applications may: so if you wish to incorporate a checksum digit into a DOI you may. This could be useful for some other application. You may use as the suffix an existing string with a checksum (e.g. ISBN). You can also calculate the checksum across the whole DOI if you wish (that would be akin to what the EAN/UPC does when it encapsulates an ISBN). Such a use of checksums in a particular
DOI application could be a rule of the DOI Application Profile concerned: "your DOIs must include a checksum".
For more on this topic, see the
DOI Handbook chapter
Numbering.
13. What is the relationship between a DOI and other standards?
The Digital Object Identifier (DOI) is a system for resolution of identifiers to global services. It uses open standards such as the Handle system and indecs framework, and can integrate with existing identifiers (they can be incorporated as a suffix into a DOI) and with other network services. DOI builds on open Internet standards and works with information industry bodies wherever possible to ensure compatibility and interoperability.
For more on this topic, see the
DOI Handbook chapters
Introduction,
Numbering,
Resolution and
Metadata.
14. What is the relationship between a DOI and other development efforts?
The International DOI Foundation is a member of some standards organizations, and maintains a number of liaisons or alliances through memberships and/or exchange of information with others, which allow us to act as a collaborative interface in discussions on standards and infrastructure development across the spectrum of intellectual property and technology communities. This provides advantages both to members of the Foundation (who may otherwise not be able to participate in all of these discussions) and to the strategic partners (who deal with IDF as a common voice for the intellectual property community in this area).
The IDF participates in the management and governance of two technology development activities where it is a major user: the Handle System, and the indecs framework.
In addition the IDF has a number of other relationships with significant development and standards activities in many areas of intellectual property and technology. Some of these are specific to particular application areas, and are undertaken in order to seed activities and outreach from the DOI to potential implementations. This list is expanding and we welcome expressions of interest from organizations who wish to establish such a relationship.
For more on this topic, see the DOI Handbook chapter
The International DOI Foundation.
15. What is the relationship between the DOI System and the Handle System?
The DOI system is an application of the Handle System (a resolution system) to intellectual property. It is more than the Handle System: it adds to the Handle System an approach based on structured associated metadata, policies, procedures, business models and application tools. Initial implementations are now being supplemented by increasingly sophisticated value-added tools for metadata management and content management, which will use the Handle System multiple resolution function. The IDF participates in the management and governance of the Handle System, together with other stakeholders.
For more on this topic, see the
DOI Handbook chapter
Resolution.
Additional
Handle System FAQs can be found on the Handle System Web site.
16. What is the relationship between the DOI System and the indecs framework?
DOI is an implementation of the indecs metadata framework. In addition, IDF participates in the management and governance of the indecs framework, together with other stakeholders. IDF is one of the organisations which developed the original indecs framework and is now developing it further. The indecs approach is fundamental to DOI's design.
For more on this topic, see the
DOI Handbook chapters
Metadata and
The International DOI Foundation.
17. How do I participate in DOI development?
Options include: working with a Registration Agency and
obtaining a DOI prefix and assigning DOIs on an experimental basis;
joining an IDF working group to work with others in a defined problem area; or
joining the IDF as a full member, with rights to participate in all working groups.
For more on this topic, see the
DOI Handbook chapters
Registration Agencies and
The International DOI Foundation.
18. Is the DOI relevant to rights transactions?
Yes. Fundamental to rights transactions are the concepts of unique identification and appropriate structured metadata. DOI implements the indecs approach, which has at its heart the concept of rights management. IDF has introduced the concepts of DOI and indecs into many digital rights management activities such as MPEG-21, OEBF, TV-Anytime, etc.
For more on this topic, see the
DOI Handbook chapters
Metadata and
The International DOI Foundation.
19. How do I develop a DOI Application?
Applications can range from DOIs being a persistent redirection to a single URL (which is easily accomplished) to advanced applications and services. DOI multiple resolution and defined metadata in Application Profiles ensure interoperability; the starting point for such advanced applications is the registration of a set of metadata appropriate to the particular community use being conceived. An Application Profile is built in a structured way using the principles of indecs. DOI does not mandate a single metadata standard; you may use any existing metadata standard; it does however require that for full interoperability the metadata set be mapped to the indecs Data Dictionary.
For more on this topic, see the
DOI Handbook chapters
Metadata and
Applications.
20. Does the IDF intend to restrict in any way the usage of the DOI System?
There are very few restrictions placed on DOI applications. However they must abide by the rules of the IDF, and must be applications which respect appropriate legal frameworks of intellectual property such as those of the World Intellectual Property Organisation.
Some restrictions have been placed temporarily, designed to ensure that the system expands in a controlled way: for example, initial applications were restricted to single point resolution (this restriction has now been lifted); DOIs are currently applied to any creation, but not yet to entities such as people and agreements. The DOI concept could be applied to any such entity but our initial applications were confined to describing the intellectual property rather than its users or uses as this area is the best developed and the one where most need has been demonstrated.
Registration Agencies and registrants abide by rules of the system, which are intended solely to maintain a level playing field. These mandate policy rules - for example that no consolidated data about use of a specific DOI is made public or available to other than the registrant. They also mandate rules as to syntax and services.
For more on this topic, see the
DOI Handbook chapter
Policy.
21. Can't I do all of this with current technologies on the Web?
No. DOIs are designed for use in any digital networks, not just the World Wide Web, which is only one recent aspect of the evolution of digital networks and the use of digital objects within them. DOIs can be used in open or proprietary digital networks in broadcasting, multimedia systems, or indeed any conceptual framework. DOIs can be thought of as an abstract specification which have a reference implementation in the current internet technologies.
Even on the Web, only some aspects such as single redirection can be accomplished with some existing technologies. Developing concepts such as Web Services promise to make available other tools; Metadata tools such as RDF may eventually be readily usable to describe indecs relationships: we welcome these as synergistic efforts. However no other current technologies offer the same packaged combination of multiple resolution; well-formed metadata; semantic analysis and mapping to metadata schemes; social infrastructure; and non-proprietary non-commercial operation supported by a wide range of content and technology providers.
Since identifiers like DOIs deliberately set out to provide advantages over existing, but widely deployed and implemented, mechanisms such as DNS and http, they need to be able to use those existing mechanisms. This is done via gateways into those existing widely implemented schemes. A gateway provides a means of accessing the functionality of one server through another. For example, a DOI proxy server (http://dx.doi.org) is used to convert DOI requests into http requests and vice-versa.
For more on this topic, see the
DOI Handbook chapters
Numbering and
Resolution.
22. I'm not an original publisher or producer of information: can I use the DOI System?
Yes: DOIs can be used by anyone, independent of the applications that may have been originally devised by the registrant. Particular communities may develop applications which involve assigning DOIs not by the original publisher but by other parties appropriate to that sector of interest. DOI users can be at any point in an information chain -- intermediary, retailer, user, producer, agent, etc, in the same way as the physical bar code is useful to (and used by) a range of retailers, logistics companies, re-sellers etc even though the code is originally assigned by a manufacturer.
Of course, we need to ensure that we don't get every party in the supply chain assigning their own DOIs to the same entity, which would be inefficient. This is obvious in the case of existing identifiers (for example, ISBNs are assigned to books by the publisher, using the ISBN agency, not by authors, booksellers, wholesalers or libraries). But it may not be obvious in the case of new areas where the supply chain rules have yet to evolve: here there may need to be some discussions and agreement in the community about what identifiers are allocated by who. Even in traditional supply chains, there may be other related and relevant identifiers used by people other than the DOI assigner (like stock-keeping units (SKU) identifiers, pallet identifiers, publisher identifiers, library catalogue numbers, etc. New linkages may also arise between these, and they can be carried out through DOIs.
The DOI system can help to ensure smooth operation in these supply chains by defining business rules for a particular DOI Application Profile. These can state who in the supply chain is responsible for assigning a DOI in that particular application: rules agreed and defined by the user community, not by the IDF. The DOI system can also help by creating automated links: if there are related DOIs in other Application Profiles a link can be made using DOI multiple resolution; if there are other forms of identifiers not in the form of DOIs, like SKUs, these can be carried as part of the DOI metadata.
For more on this topic, see the
DOI Handbook chapters
Numbering and
Resolution.
23. How does DOI metadata relate to the Dublin Core Metadata Initiative?
Dublin Core aims to be an easy-to-create and maintain descriptive format to facilitate cross-domain resource discovery on the Web. "Qualified Dublin Core" supports the use of DC elements as the basis for extended but simple statements about resources, rather than as a foundation for more descriptive clauses. Complex descriptions may be necessary for some Web resources and for some purposes, such as administration, preservation, and reference linking. However, complex descriptions require more expressive data models that differentiate between agents, documents, contexts, events, and the like. This is achieved through the indecs model. While DC starts from a small group of "core" elements, and DOI Application Profiles include a small group of "kernel" elements, the two do not serve the same purpose. The DOI kernel is derived from a comprehensive data model and has strict rules for mandating implementation. The DOI Resource Metadata Declaration provides a tool set for extending metadata declarations to any desired set of entities, comparable therefore to DC-qualified but with the significant difference of a basis in an underlying comprehensive semantics to ensure consistency of all declarations for any purpose.
Any DC scheme may be used as the basis for developing a DOI Application Profile, though the DC metadata may need to be supplemented or further defined in the mapping to the indecs Data Dictionary, depending on the precision with which the DC term has been defined.
The DOI Metadata System enables semantic interoperability between APs devised for any purpose (not only simple description but more complex events), so that "cross-domain" tools and applications (those which reference DOIs across more than one AP) can do so consistently and effectively. Such semantic interoperability will be required for widespread digital use of information from multiple sources.
For more on this topic, see the
DOI Handbook chapter
Metadata.
24. Where do you put a DOI and what does it look like to a user?
You may put a DOI anywhere you like. A DOI may be printed or made explicit within a digital object; or it may be hidden by e.g. underlying a hyperlink. Therefore it can either appear as a DOI, or the user may never know that a DOI has been used to "power" her transaction.
For more on this topic, see the
DOI Handbook chapter
Numbering.
25. How do I use a DOI in a Web Browser?
Applications using DOI can be constructed on a web site with full functionality behind the scenes. For some applications, this may require additional functionality such as that supplied in the Handle system: users may find it helpful to load a small free plug-in if the browser they are using does not support URN resolution. DOIs are URIs (URNs) not URLs: the distinction is that they are names not locations. Most web browsers support locations (URLs) but have limited functionality for names, though this is expected to improve substantially in the near future. However, DOIs are useable with browsers immediately:
There is a freely available "resolver plug in" that can be downloaded from
http://www.handle.net/resolver/. For both Netscape and Microsoft IE browsers, the plug-in extends the browser's functionality so that It will recognize a DOI in the form "doi:10.1000/123", and resolve it to a URL or other file type the browser recognises. The user simply "clicks" on the DOI (or types the DOI into the address line in their browser) and the DOI is resolved directly.
Alternatively, without the need to extend their web browsers' capability, users may resolve DOIs that are structured to use a DOI proxy server (http://dx.doi.org), which "translates" a name using URL syntax. The resolution of the DOI in this case depends on the use of URL syntax: for example doi:10.1000/123 would be resolved from the address: "http://dx.doi.org/10.1000/123". Any standard browser encountering a DOI in this form will be able to resolve it.
Many browsers, such as IE6, support URNs as bookmarks, so DOIs can be saved in that form.
For more on this topic, see the
DOI Handbook chapter
Resolution.
26. What is the relationship between DOI and XML?
The DOI System makes use of XML (eXtensible Markup Language), and XML is entirely compatible with DOI. The expression of DOI metadata in XML is recommended both for kernel metadata and for DOI Application Profile metadata extended from the kernel. The indecs data dictionary and the DOI Resource Metadata declaration both allow the use of XML expressions, commonly used for metadata transport and messaging.
It seems likely that the relationship between DOI and XML will grow over time. One obvious link is in developing DOI Application Profiles for the various emerging XML schemas for industry-specific uses, such as NewsML: when such a scheme has been developed, DOIs provide an obvious way of adding functionality (persistent identification, interoperable metadata mappings, multiple resolution framework, etc.) to that schema for practical uses.
The linking of entities in XML is very different to the linking of entities with DOIs, as the two serve different, complementary purposes. XML entity resolution is concerned with the construction of an XML document or message; it exists to support the assembly of XML documents from components. DOI resolution, on the other hand, deals with information about an identified entity and linkage of intellectual property entities and information about those entities. DOIs may of course be used to identify entities which are "marked up" in an XML schema; but not every tagged entity in an XML schema may merit a DOI, unless there is a need for separate management of that entity (functional granularity).
Several languages have been constructed using XML that support functions complementary to DOI: e.g. XLink is a language that allows XML elements to be made into links, which specify relationship types and behaviour characteristics between sets of resources; the Resource Description Framework is another language that can be expressed in XML and allows properties of an identified resource to be described. Although neither of these technologies are yet mainstream, they have similar characteristics to, and can be used with, DOIs. The IDF is actively pursuing such usages and monitors XML developments closely.
For more on this topic, see the
DOI Handbook chapter
Metadata.
27. How can the DOI be used to locate my specific local copy, which may have
different access rights?
The Digital Object Identifier (DOI) is a system for resolution of identifiers to global services. However it can be used with other complementary technologies, such as OpenURL, to allowing the contextualization of requests to those services to local requirements.
Registration Agencies such as CrossRef offer practical implementation of the DOI with such local linking technology. A typical example is that a library may well wish to resolve to a specific instance of a content item -- such as a cached copy which it has access rights to -- rather than a publisher-held "generic" copy. It is appropriate to split this into separate global and subsequent delegated local resolution steps, since a globally-maintained database is clearly the wrong place to hold information on every local collection.
Basic OpenURL write up can be found at
http://www.crossref.org/03libraries/16openurl.html.
It is also possible to deal even with individual copies by identifying them by DOIs, though it may not always be appropriate. DOIs can be used to identify any resource: in CrossRef for example, the DOI is allocated to the abstraction representing the article work (that is, different formats etc such as pdf versus Word are not separately identified: we can think of the DOI as identifying the class of all formats and copies). In other applications, different DOIs might be allocated to different formats, or even to individual instances.
For more on this topic, see the
DOI Handbook chapter
Resolution.
28. "Persistent identification" is an accepted concept:
what does the DOI add to this?
The need for persistent identifiers is well recognised in many areas (particularly from the library, archives, and government communities), but the next step (adopting a practical implementation such as DOI) is not yet so readily comprehended. There is a fundamental difference between recognising the need for persistent identifiers through a technical scheme (like URN), and the practical implementation of this (which inevitably has associated costs but also associated added value: a DOI is a URN and URI implementation). The key point is not about DOI "versus" an alternative scheme; it is about technical versus business infrastructure, and the need for additional implementation work for the use of any persistent identifier.
The implementation of persistent identifiers adds value, but necessarily incurs some costs (in number registration, infrastructure maintenance, and governance). There is a widespread recognition of the advantages of assigning identifiers; and a widespread misconception that an abstract specification (like a URN or URI) actually delivers a working system rather than a namespace that still needs to be populated and managed. A common misperception is that one can have such a system at no cost. It is inescapable that a cost is associated with managing persistence and assigning identifiers and data to the standards needed to ensure long-term stability.
If adding a URL "costs nothing" (which itself ignores some infrastructure costs), why should assigning a name? It is indeed possible to use any string, assigned by anyone, as a name -- but to be useful and reliable any name must be supported by a social as well as technical infrastructure that defines its properties and utilities. URLs for example have a clear technical infrastructure (standards for how they are made), but a very loose social infrastructure (anyone can create them, with the result that they are unreliable alone for long term preservation use as they have no guarantee of stability let alone associated structured metadata). Product bar codes, Visa numbers, and DOIs have a tighter social (business) infrastructure, with rules and regulations, costs of maintaining and policing data -- and corresponding benefits of quality and reliability.
Like any other piece of infrastructure, an identifier system (especially one which adds much value like metadata and resolution) must be paid for eventually by someone. The DOI is designed to work with any business model, ranging from free assignment to assignment on a commercial basis.
For more on this topic, see the
DOI Handbook chapters
Introduction and
Policy.
29. What data is associated with a DOI?
The simplest DOIs (such as those in the earliest implementations of DOI) are essentially redirection from a persistent name (the DOI) to a changeable URL. The information associated with the DOI in the DOI system is therefore simply the URL and relevant administrative information for managing the DOI. These are now known as DOIs of the Zero Application Profile.
However, in more sophisticated applications, a DOI has additional associated data which help characterise the identified entity and which can be used to build services related to the identified entity. The Application Profile (AP) is a key example of such additional data. APs are used to group sets of DOIs which have similar characteristics, such as the same metadata schemas and business rules for DOI assignment. Thus, discovering that a given DOI is a member of a given AP is a shortcut to knowing what metadata elements can be found for the DOI, for knowing who is responsible for maintaining the DOI, and for any other characteristic that is common to the set of DOIs which are of that AP.
DOI data which is not common to all members of an AP is associated with an individual DOI on a one-to-one basis. All Application Profiles beyond Zero contain a minimum of some publicly declared metadata (the kernel metadata) which is sufficient to provide users and applications with a basic description of the entity identified with a DOI.
The indecs metadata framework is the basis for normalizing across different metadata schemas used by different communities, enabling communities to build schemas which meet their needs. Application Profiles bring together a number of things, all along the lines of classing DOIs for convenience in dealing with large numbers of them while still allowing for individual differences. That includes metadata, policies, and services.
Application Profiles are articulated by defining a data type within the DOI handle record. The resolution system is able to retrieve this data; clients (such as that implemented in the DOI Adobe plug-in) know how to parse that data; in the case of a defined AP the client finds first the reference to the application profile data type, and then keeps looking and finds some URI referenced by the AP definition. The job of the DOI (handle) client library is to go off and get the data, wherever it lives. Then it hands that data off to whatever asked it to do that (the client such as the DOI Adobe plug in) in the first place.
For more on this topic, see the
DOI Handbook chapter
Applications.
30. What is an Application Profile and what data does it associate with a DOI?
Every DOI is associated with one or more Application Profiles (APs). APs, which will themselves be identified by DOIs, are abstractions used to group DOIs into sets in which all DOIs of the given set, or AP, share a metadata schema, business rules for DOI assignment, and other common characteristics. An AP consists of at least a set of structured metadata elements, plus some rules (policy, business and procedural rules, not all necessarily automated). AP metadata, business rules, and other specifics will be determined by the community defining the AP; in practice this is likely to be, or to closely involve, the RA concerned.
APs are an aid to using DOIs, enabling all DOIs assigned to e.g. journal articles to behave in a consistent and predictable fashion, that would necessarily differ from the characteristics and behaviour of DOIs assigned to e.g. recorded music. For example, if one intended use of DOIs is to lead to metadata for the identified entity and the metadata for journal articles and recorded music, outside of a small common kernel, will be quite different. This is only one example: in fact the data structures and potential services associated with DOIs by their assignors will not only depend upon the type of entity being identified but also by the intended usage of the DOI. An Application Profile groups together characteristics not only of the type of identified entity (roughly what has been called the "genre") but also the intended usage, or application, of the DOI.
The core elements of an AP will be a metadata schema and various business and procedural rules. The business and procedural rules will cover such policies as "who can assign a DOI within this AP" and "what elements of metadata are public in this AP" and so on. The metadata elements common to all members of an AP will be defined through the use of the DOI data dictionary, which is an implementation of the indecs data dictionary developed as part of the ISO MPEG-21 process. Entities within this data dictionary will be assigned a unique iid (indecs identifier). In the DOI implementation of the data dictionary, each iid will also be a DOI (DOI.iid). This standardization of elements will allow developers, using a planned registry of APs, to know which elements are shared by which APs. Beyond metadata and business rules, APs may also include standard services, e.g., any DOI of AP X may be sent as an http query to location Y in order to request rights information. The use of DOIs to identify APs brings the standard benefits of indirection, that is, location Y in the above example can change without affecting the millions of DOI records that might reference AP X.
The DOI/AP relationship can be in one of three states:
Zero AP: no AP is associated with this DOI. Most DOIs are currently in this state.
- Base AP: the only data associated with this AP is the kernel metadata (the minimum set of 6 elements, plus the DOI value and the DOI AP name).
- Full AP: the kernel metadata plus other metadata (which must be mapped to the DOI data dictionary) plus business rules and procedures plus any other common elements such as available services. We expect a number of different APs to evolve, roughly corresponding to communities of interest.
APs are intended, as are the other DOI mechanisms, to serve as infrastructure for the coherent management and use of intellectual property. While they will be defined and maintained by communities of interest, probably as represented by IDF Registration Agencies, they may also serve as convenient mechanisms for associating third party services with classes of DOIs. Registries will be established for this purpose. The specific rules and procedures for relating a given AP to third party services will be determined by the creators of that AP. To the extent that an AP is public, of course, anyone may operate a service applicable to that set of DOIs.
New APs must be approved by the IDF and centrally registered, to minimise duplication of effort and maximise interoperability. Defined APs will be made available to others who wish to construct new APs or re-use existing APs.
Registration Agencies add value at various levels by offering services to registrants. These services can include the definition of APs, and the one-off mappings needed in creating these from metadata sets already in use in the particular community concerned. There are two mandatory requirements for an RA using the DOI metadata system:
- To declare the DOI kernel metadata in a standard format
- To map the full Application Profile to the DOI standard data dictionary
Once an AP is defined, RAs can offer services in allocating DOIs within this AP, ensuring the AP information is completed, populating the DOI system with allocated DOIs, maintaining up to date records, etc. Consultancy on implementation, design of new applications, etc are other obvious areas for business development by RAs.
For more on this topic, see the
DOI Handbook chapter
Applications.
31. What data is held in the resolution system and associated
with a DOI?
The core resolution system for all DOIs is the Handle System. Each DOI is registered as a handle in the Handle System and associated with a set of typed values. These values are returned in response to a resolution request for a given DOI. The values can be changed while the DOI remains constant, giving the DOI its basic qualities of being both actionable and persistent.
DOIs, with the exception of certain special cases, are registered with a minimum of one value, of the type "URL". This can generally be thought of as 'location' but it really functions as the default value of the DOI in the context of the web and may not actually be the location of the identified entity. For anything beyond the simplest DOI, the declaration of an AP is an additional value within the Handle record, with its own data type. The DOI kernel metadata has as one element, "DOIApplicationProfile," which will reference this same data.
The association of an AP with a DOI may be sufficient, or may require additional data within the handle record. If services are associated with a given AP, for example, but the location of the service varies with DOI, then the declaration of the AP may need to be accompanied by the location of the service specific to that DOI. Similarly, two Registration Agencies (RAs) could share an AP but, in order to determine which RA had registered a given DOI, the AP declaration would have to be accompanied by an indication of RA. The precise mechanisms for accomplishing these tasks will be defined by the AP. At a certain level of variability across DOIs within an AP, of course, it may be better to create an additional AP rather than stretch one to cover too many different cases. Functional requirements will determine which is the case.
Additional data, beyond APs and any DOI-specific AP data, can be associated with a DOI as it is found useful. While the association of services and DOIs can be done through the AP mechanism, it may be that some services are best associated with each individual DOI and not through an already related AP. If this additional data is related using the Handle System, new data types can be created, as the Handle System typing mechanism is extensible. As with APs, data types must be approved and centrally registered, with the aim of minimising duplication and maximising interoperability.
Where data types require entities which are already defined within the DOI Data Dictionary, the DOI.iid will be referenced. Data types will also be identified by means of DOIs.
The combination of data typing through the resolution system, and interoperable metadata accessed through an Application Profile, provides a powerful set of tools for the creation of DOI services.
For more on this topic, see the
DOI Handbook chapter
Applications.
32. DOI stresses interoperability, resolution and metadata -- how
do they relate to each other?
The Application Profile concept in DOI provides linkage between the resolution mechanism used in the DOI (handle) and the structured metadata approach (indecs). DOI's handle resolution allows identifier interoperability - i.e., you can encapsulate an ISBN or other identifier as a DOI and then resolve it to any current state data. An Application Profile is the hook into metadata semantic interoperability -- i.e. you can use whatever metadata schema your community finds useful with your DOI, but mapping through the AP provides a way of talking (semantically interoperating) with other objects that are encoded in different schema). The AP approach is built on indecs principles also adopted elsewhere such as ISO MPEG 21.
DOIs resolve to one or more typed values in the Handle System and it is these typed values that determine client behavior. The predominant client at the moment is a proxy, or gateway, at dx.doi.org that takes normal http GETs, e.g., http://dx.doi.org/10.123/456 where the DOI is 10.123/456, resolves the DOI in the Handle System looking for URLs and returns those URLs to the originating web browser as http re-directs. This is how most DOIs currently implement a single level of indirection. Using a dedicated client, such as a plug-in for Acrobat, opens this up considerably, letting us use different data types for different purposes.
For more on this topic, see the
DOI Handbook chapter
Applications.
33. What is a "DOI Service"?
A defined result from a defined action i.e., do X and the result will be Y. DOI Services perform specific functions when presented with data from DOI Application Profiles. DOI services exchange data, share tasks, and automate processes over the Internet by using the information associated with a DOI. The term was coined in analogy to "Web services": for DOI applications on the Web, DOI services would be Web Services. As a new class of Internet-native applications, web services promise to increase interoperability and lower the costs of software integration and data interchange: these aims are clearly identical to those of DOI (and its underlying tools of resolution -- Handle System -- and metadata -- indecs framework). Based on unambiguous rules, DOI services make it possible for computer programs to communicate directly with one another and exchange data about intellectual property entities regardless of location, operating systems, or languages.
The combination of data typing through the resolution system, and interoperable metadata accessed through an Application Profile, provides a powerful set of tools for the creation of DOI services.
For more on this topic, see the
DOI Handbook chapter
Applications.
34. What information about a DOI is publicly available?
Once a DOI is assigned, anyone may resolve that DOI without charge. At least some information will always be available on resolution.
The information available on resolution depends on the Application Profile (AP) of the DOI. DOIs can be associated with one of three categories of AP Public availability of information is as follows:
- Zero AP: no data other than a URL is registered and therefore only that is available.
- Base AP: the kernel metadata set (the minimum set of 6 elements, plus the DOI value and the DOI AP name) is registered with each DOI within this AP. The values of each DOI's kernel metadata, the minimum required to permit basic recognition of the entity to which the DOI is assigned, must be publicly available, so that a basic description of the entity the DOI identifies can be accessed by any user and services built which can interpret DOIs.
- Full APs: these contain the kernel metadata set, plus other metadata values (which must be mapped to the DOI data dictionary). Whilst the AP scheme must be made available (so that users can determine which metadata fields are associated with the DOI), the actual values of any metadata for each DOI need not be; whether some or all of these are made available will be determined by the registrant or AP rules.
As the DOI system evolves, it is gradually moving from zero to full APs.
Uses of the DOI which are restricted and not public (either permanently or temporarily) require special declarations and treatment. Private use of the DOI may have advantages either in conferring on a private scheme the benefits of interoperability, persistence, well-formed data structures, and governance structure; and in allowing the subsequent migration of private identifiers into the public realm without having to reassign identifiers with a policy or technical change which allows them to be private (and potentially switched to public) if desired.
For more on this topic, see the
DOI Handbook chapters
Applications and
Policy.
35. What are the benefits of the DOI for Publishers, Intermediaries, and users?
The DOI System offers a unique set of functionality:
- Persistence, if material is moved, rearranged, or bookmarked;
- Interoperability with other data from other sources;
- Extensibility by adding new features and services through management of groups of DOIs;
- Single management of data for multiple output formats (platform independence);
- Class management of applications and services;
- Dynamic updating of metadata, applications and services.
For users, these features provide the ability to:
- Know what you have
- Find what you want
- Know where it exists
- Be able to get it
- Be able to use it in a transaction
For more on this topic, see the
DOI Handbook chapter
Introduction.
36. How do I apply to become a Registration Agency?
Any organization that can represent a defined "community of interest" for alloca